Understanding AI Foundation Models: A Comprehensive Guide to the 6 Most Common Architectures
1. LLM(Large Language Model)
Representatives: GPT series, Claude, LLaMA, DeepSeek-V3, Kimi K2, GLM-5.
The undisputed core model type, based on the Transformer architecture and trained on massive text corpora, its core task is to predict the next token. ChatGPT, Claude, Gemini, Kimi, and DeepSeek are all built on top of it. Nearly all AI products rely on an LLM as their foundation.
Capabilities are improved by increasing parameter scale, including layers, attention heads, and MLP dimensions. GPT(Generative Pre-trained Transformer) is a classic subclass of LLM rather than a synonym.
LLM is the general term for large language models, while GPT specifically refers to the autoregressive + pretraining + Transformer paradigm.
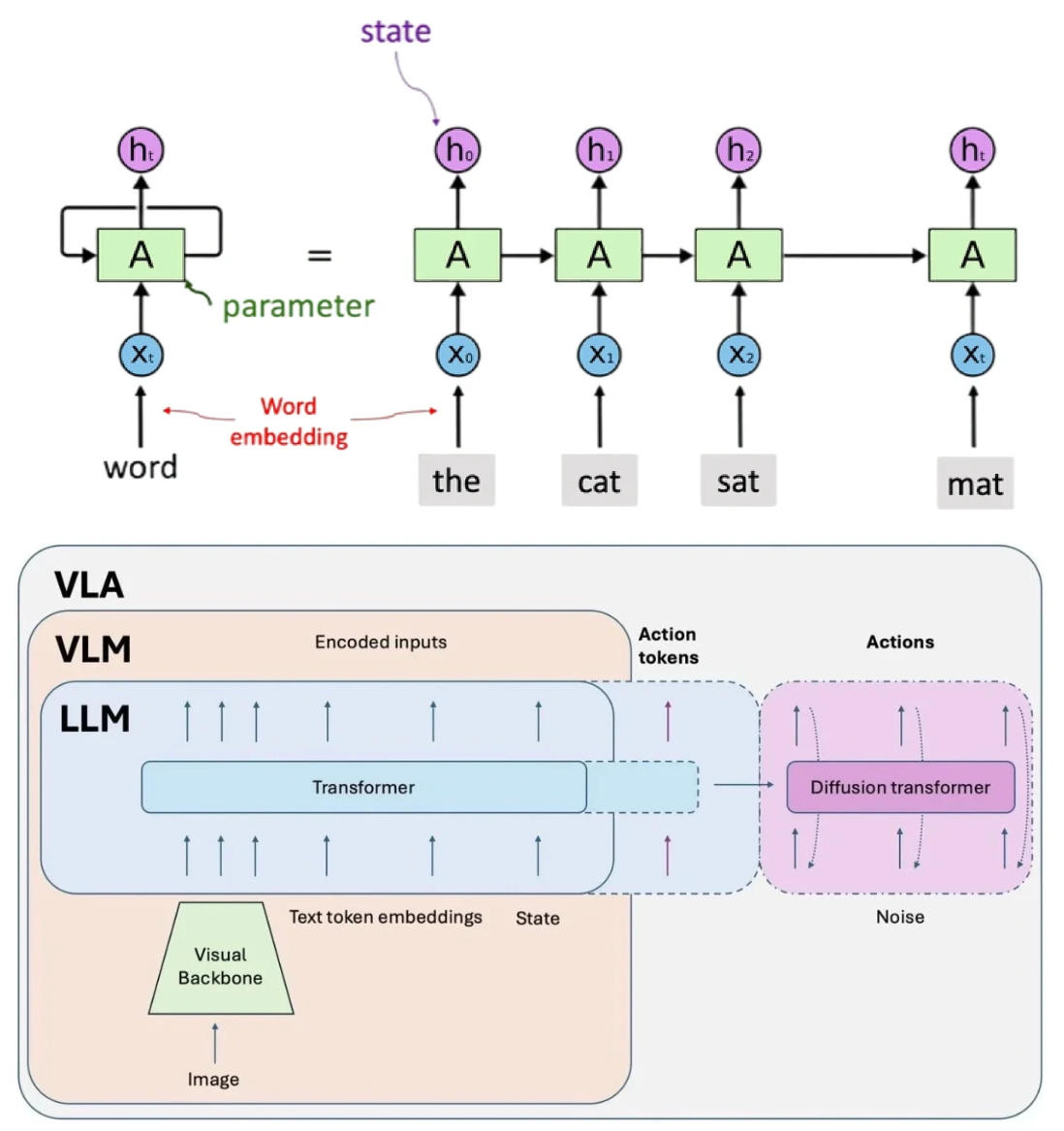
Most modern LLMs are built on a Decoder-Only architecture. By using a Causal Attention Mask, they generate tokens autoregressively from left to right, which is the foundation of their powerful generation capabilities.
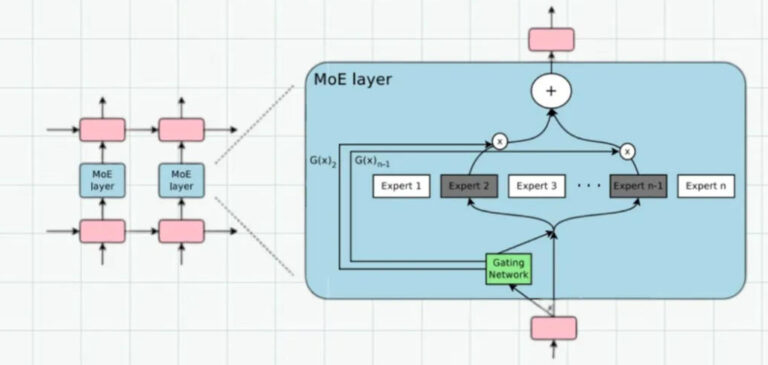
2. MoE (Mixture of Experts)
Representatives: Mixtral, DeepSeek-V3, Kimi K2/K2.5, GLM-5, LLaMA 4.
Strictly speaking, MoE is not an independent model category but an architectural strategy.
The core idea is to split the FFN (feed-forward network) inside a Transformer block into dozens or even hundreds of expert subnetworks. During each inference step, only a small number of experts are activated through a router.
3. DDR Training Procedure During SSD Power-up
After covering hardware and software architecture, we now break down the SSD’s “input/output channels”: the front-end protocol, which communicates with the host, and back-end control, which communicates with NAND flash. These two parts directly determine SSD transfer speed, compatibility, and expandability, and are key criteria for enterprise selection.
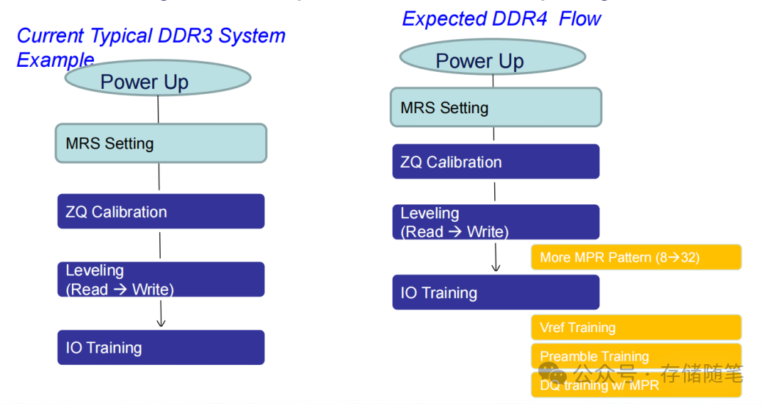
3.1 Phase 1 – Power-Up Initialization
Goal: transition DRAM from RESET to IDLE and configure baseline operating parameters.
Power & Reset Sequence:
- After SSD power-up, apply VDD (core) and VDDQ (data) to DRAM and wait for rails to stabilize (commonly ~100 us).
- Release RESET_n and assert clock enable (CKE).
- Start the differential clock (CK_t/CK_c) at a low rate (e.g., 200MHz), then step to the target frequency (e.g., 1600MHz for DDR-3200).
Mode register setup (MRS commands) Controller programs DRAM mode registers in JEDEC order (MR0->MR1->MR2_>…). Typical settings:
- MR0: CAS latency (CL), burst length (BL, typically 8), self-refresh modes.
- MR1: Drive strength (e.g., DS=RZQ/4), ODT setting (e.g., RTT_NOM=240Ω).
- MR2: CAS write latency (CWL), dynamic ODT (RTT_WR).
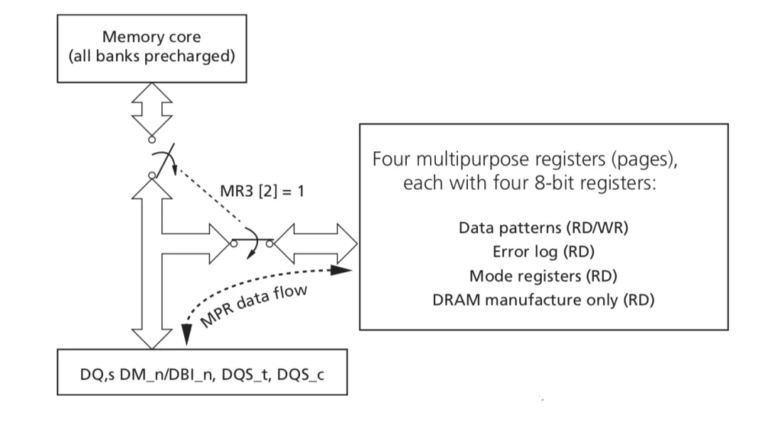
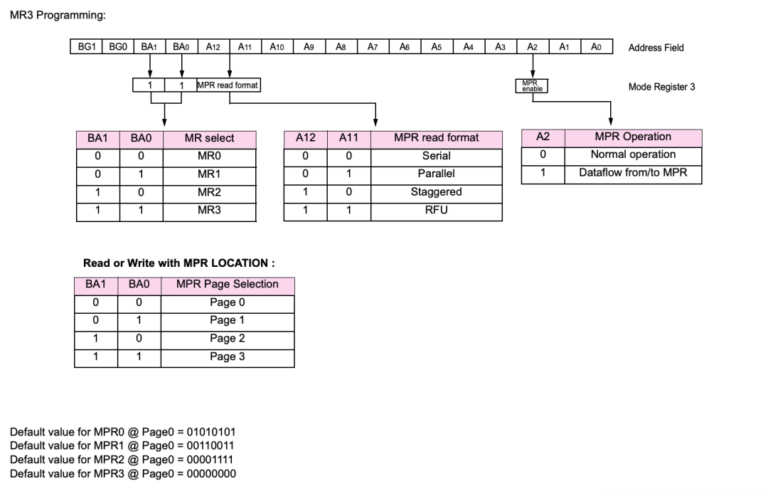
- MR3: Enable MPR (Multi-Purpose Register) mode to prepare for read/write training.
Example: a DDR4-3200 configruation might use CL=16, CWL=14, BL=8, RTT_NOM=240Ω.
Precharge & Refresh:
- Issue PRECHARGE ALL to close active rows in each bank.
- Issue REFRESH to stabilize DRAM cell charge after power-up.
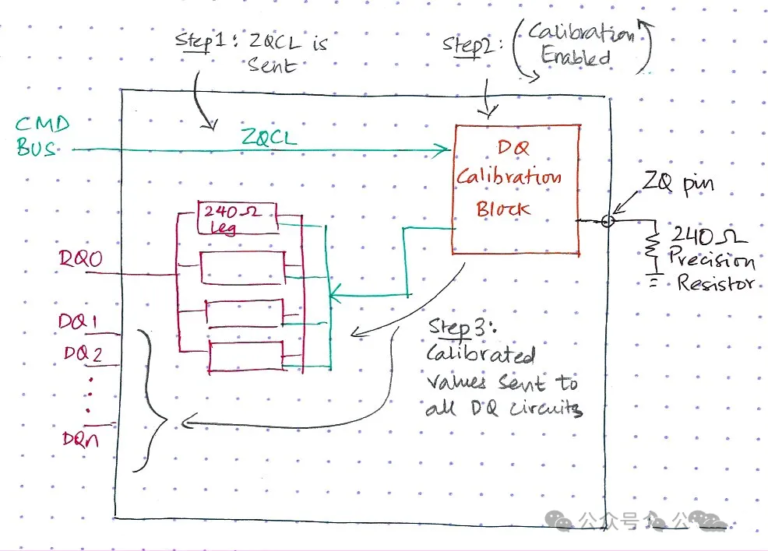
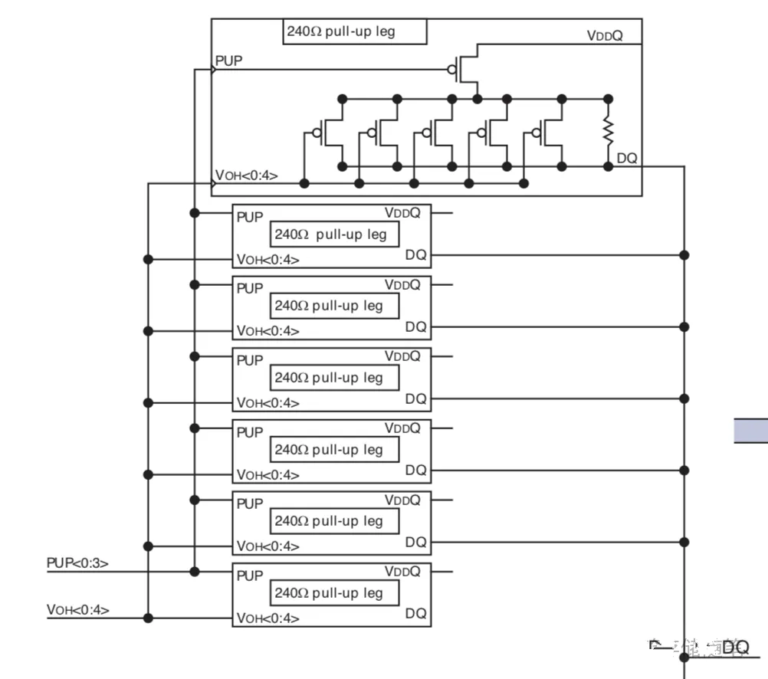
3.2 Phase 2 – ZQ Calibration
Goal: calibrate DQ drive strength and ODT to match JEDEC target impedance (e.g., 240Ω).
Hardware basis:
- DRAM integrates a ZQ calibration module (comparator and resistor tuning blocks).
- The SSD PCB ties the DRAM ZQ pin to a precision external resistor (e.g., 240Ω ±1%) as a reference.
Calibration flow (ZQCL example):
- Controller issues ZQCL (ZQ Calibration Long) to start full calibration.
- DRAM’s ZQ module forms a Thevenin divider tith the external ZQ resistor; a comparator adjusts VOH[0:4] (drive strength control bits) until the divider node equals VDDQ/2.
- Calibrated VOH values are applied to the DQ driver circuits.
- Optionally, ZQCS (ZQ Calibration Short) is used for quick runtime recalibration.
Verification:
Post-calibration goals: DQ output impedance error ≤5%; ODT error ≤10%. Engineers typically verify signal reflection coefficients with an oscilloscope (S11) target around |S11| ≤-15dB.
3.3 Phase 3 – VrefDQ Calibration (VrefDQ Training)
Goal: adjust the data sampling reference voltage (VrefDQ) so logic ‘0’ / ‘1’ decisions are robust.
VrefDQ role:
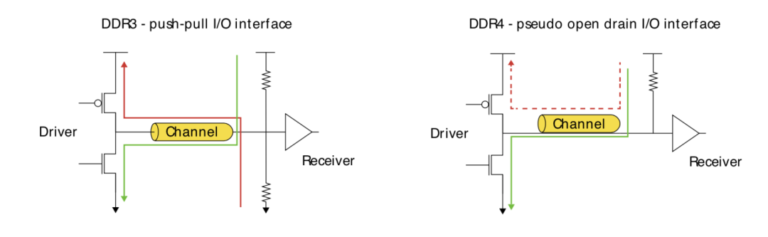
DDR4 uses a pseudo-open-drain interface; receivers lack an internal divider, so VrefDQ defines the decision threshold (commonly between ~0.3VDDQ and 0.6VDDQ). For VDDQ=1.2V, the practical VrefDQ tuning range is roughly 0.36~0.72V.
Calibration flow (2-D sweep method):
- Enter Vref training mode (e.g., via MR6).
- Generate traning patterns (checkerboad 0x55AA/0xAA55 or PRBS).
- Voltage sweep: step VrefDQ in small increments (e.g., 10mV) across the expected range.
- Time/phase sweep: step DQS sampling phase in fine increments (e.g., 1/64 UI) across 0~360°.
- For each (VrefDQ, phase) pair, measure BER and eye area.
- Choose a pair with BER ≤1×10⁻¹² and the largest eye area; store parameters in controller registers.
SSD-specific optimization:
Because NAND activity can couple noise into DDR channels, include simultaneous NAND read/write activity during Vref calibration to ensure the selected VrefDQ remains robust under real workload noise. Reserve ~5~10% margin when choosing operating VrefDQ.
3.4 Phase 4 – Read/Write Training
Goal: align DQS and DQ timing to maximize timing margins for read and write – the most complex stage.
DDR4 provides MPR (Multi-Purose Registers) that are commonly used to store training patterns so that the training process does not occupy NAND cache.
Preparation:
- Enable MPR mode by setting MR3[2]=1.
- Write training patterns into MPR (e.g., MPR0=0xAA, MPR1=0x55, MPR2=0xFF, MPR3=0x00).
- Verify MPR contents via READ back.
Write Training:
Goal: ensure DQ launched by the controller is sampled correctly by DQS at the DRAM side, satisfying tDQSS (DQS relative to CK) constraints (JEDEC tDQSS ≈0.9~1.1 UI).
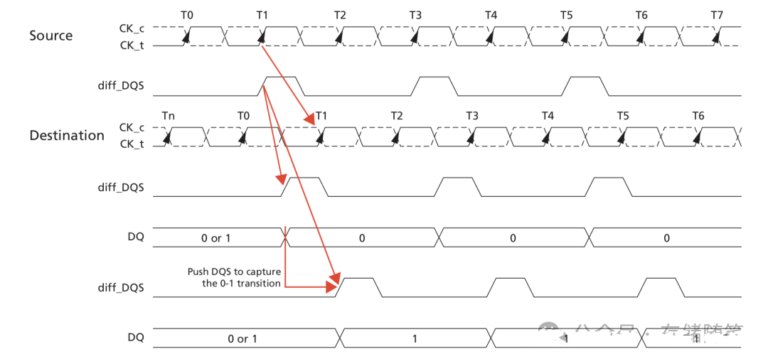
(1) Write Leveling:
- Enable Write Leveling (set MR1[7]=1).
- Controller steps DQS delay (e.g., 1/32 UI steps) while sending SQS pulses.
- DRAM samples CK on DQS rising edges and returns status via DQ.
- Controller locates the critical edge trnsition (feedback from 0->1) to align DQS with CK and locks the DQS delay per DQS group (e.g., for x8 devices DQS0~DQS7).
(2) Write Centering:
- Controller writes alternating patterns (0xAA/0x55) into MPR.
- Sweep DQ-to-DQS delay in fine steps (e.g., 1/64 UI) and read back MPR.
- Record BER at each delay and pick the center of the zero-error window as the optimal write delay so that DQ is centered relative to DQS.
Read Training:
Objective: calibrate the controller/PHY read capture so the sampling point sits at the center of the data eye.
- Enable MPR readback (MR3[2]=1) so DRAM returns MPR patterns during reads.
- Issue continuous reads; DRAM returns stable MPR patterns. Scan internal read delay registers (increment/decrement) to find the left and right eye edges (earliest and latest valid sampling points).
- Center the sampling point between the detected edges and lock the read delay registers.
- Repeat for all DQ bits to complete full-link read centering.
Alternatives / Notese
- Not all implementations use MPR for read centering: older DRAM (e.g., DDR3) lacks MPR and may use direct bank write/read of test patterns. Custom controllers may use proprietary schemes.
- MPR-based centering is a hardware-software cooperative process: firmware initiates/configures training; controller/PHY hardware performs high-speed scanning and edge detection in parallel without software intervening in tight timing loops.
4. Alternatives and Complementary Techniques
- 2-D Vref training: jointly sweep Vref and timing to find the sampling point with the largest eye; commonly used in DDR5/LPDD5 PHYs. It can complement MPR centering (MPR for coarse timing, 2-D Vref for fine tuning).
- Dynamic data-pattern calibration: write PRBS or complex patterns and measure BER during reads to infer optimal timing. This method is slower and consumes memory bandwidth but can be used where MPR is unavailable.
5. Dynamic Considerations and Pos-Training Drift
MPR/static calibration at power-up does not necessarily cover runtime dynamics. Sources of drift include:
- Environmental changes: supply ripple and temperature swings change link delay/impedance.
- Workload variation: heavy DDR activity increases crosstalk and reflections.
- Hardware aging: DRAM driver and PHY delay elements can degrade over time.
Mitigations:
- Periodic re-centering: schedule periodic read-centering (prefer MPR where available) to compensate for environmental drift. Frequency depends on environment (e.g., every 10 minutes in high-temp scenarios; every hour in stable datacenters).
- Adaptive delay compensation: high-end PHYs include VT (voltage-temperature) sensors and dynamically adjust delay registers for milisecond-scale compensation without a full retrain.
- Signal integrity improvements: PCB layout optimization (shorter traces, impedance control), better decoupling, and SerDes-like equalization techniques (Tx FFE / Rx DFE) for high-speed DDR.
- Parameter profiling and dynamic adaptation: sotre calibration profiles for different temperature/load conditions and apply matching parameter sets at runtime to shorten recalibration time.